tl;dr: github.com/ricklamers/gpt-code-ui and to run it pip install gpt-code-ui && gptcode
Alright, I’ll cut right to the chase. I’ve built GPT-Code UI because OpenAI couldn’t be bothered to give me access to their new fancy ChatGPT Code Interpreter. And most likely, you don’t have access either.
What is ChatGPT Code Interpreter? Well, it’s basically a REPL (read–eval–print loop) that’s integrated with the coding abilities of ChatGPT. You can do really neat things with it like giving it a file (e.g. a CSV file) after which you can ask it to convert the file or extract some information from the file or even use the file as input for a calculation! If you want a longer explanation you can watch this YouTube video.
API + local client
Luckily, we do have API access to the underlying model that’s being used for Code Interpreter (GPT-4 or perhaps GPT-3.5 for its speed). I figured with some glue-heavy engineering I could use the API to build my own version. With the proliferation of all kinds of local ChatGPT clients like this one and this one, I figured there was room for one more. One focused on the REPL + LLM niche for a personalized assistant that can carry out your mundane tasks by executing code for you.
Jupyter kernels
Those of you who’ve seen what I’ve been up to for the past couple of years know I’m a big fan of interactive computing experiences powered by the Jupyter project. Jupyter kernels are a language agnostic concept that give you a compute kernel that can execute snippets of code over a sort of wire protocol that connects a user stdin to a REPL and wires stdout/stderr back.
I’ve been obsessed with how to take advantage of the Jupyter project. Some time ago, over the weekend, I created a project called slack-ipython. It allows you to run Python code by exposing a Jupyter kernel as a Slack bot.
The problem with that project is that you still have to write your own code. It’s 2023, week 20 who still does that!? (Yes, in AI land we don’t just count in years anymore, things move too fast for that.)
Queue GPT code models!
The project: GPT-Code UI
I wanted the project to be as simple as possible from a local installation perspective. One of my suspicions is that OpenAI hasn’t released the ChatGPT Code Interpreter to a wider public yet is because it’s effectively exposing a cloud compute VM (albeit heavily sliced like Google Colab does) to all of ChatGPT (Plus?) users. That’s a) some serious engineering work and b) an even more serious cloud bill.
Because I don’t have free infinite cloud computing either I thought the best course of action would be to let everyone use their own good ol’ computer. (That thing you used to run stuff on before we moved everything in the cloud.)
To make it easy to get up and running I wanted the install process to be pip install gpt-code-ui and nothing more. Since the heavy lifting is done by the hosted model inference run by OpenAI most of the code that needs to run locally is actually fairly simple.
For including the frontend (built in React) I borrowed a trick from the excellent Streamlit project. You just build a web SPA client and bundle it into your Python package right before you upload it to PyPI. Technical detail: they used CRACO (Create React App Configuration Override) but I went with the more modern Vite for bundling the SPA.
For separation of concerns I decided to keep the Flask based Jupyter kernel manager separate from the main Flask app that serves the static SPA files and communicates with the OpenAI API. See the following basic architecture diagram for an overview of the main components:
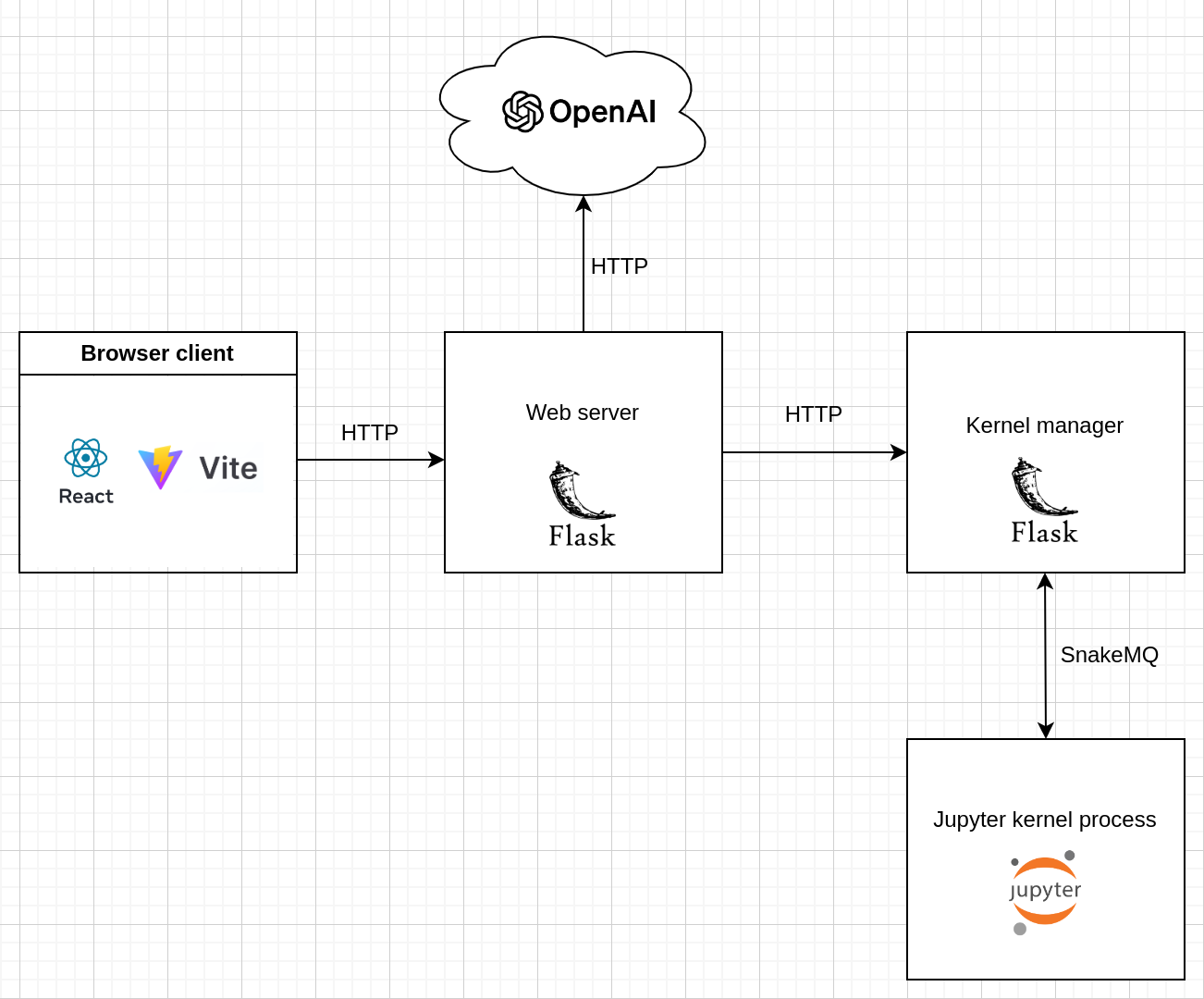
Feature list
You’re still here? Awesome! This is the good part, I promise. This thing actually works!
Here’s what the project can do (today):
- File upload
- File download
- Context awareness (it can refer to your previous messages)
- Generate code
- Run code (Python kernel)
- Model switching (GPT-3.5 and GPT-4)
So you can do things like upload a CSV file and ask it to remove a column, save the file and print a download link. Even after seeing it over 50 times during development, the fact you can do that in 2023, week 20 blows my mind 🤯
What can I do with this?
Here is an example I think is really neat. I upload a weights.txt file and ask it to find the optimal item configuration posed as the knapsack problem.
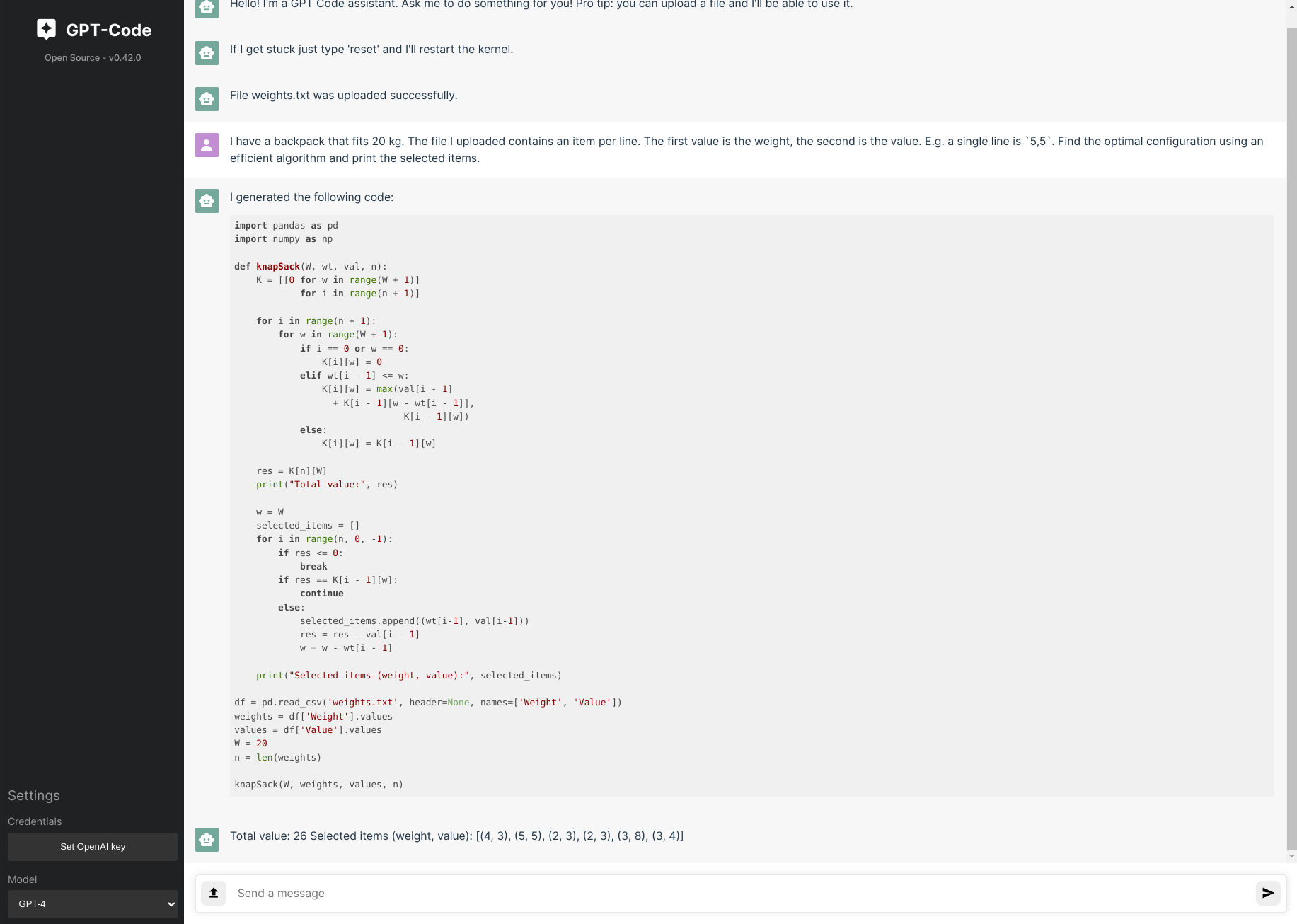
A different kind of engineering
This is a bit of a tangent bit I feel like it’s still slightly on topic. During development I came up with some tricks that felt pretty magical.
File upload context injection
First, I needed the let the model know somehow what the filename was of the file the user uploads. The first naive simple solution I came up with ended up working surprisingly well.
To give the model context of the previous instructions the user has given I maintain a deque limited to 4K characters (safely below the context window size of 4K tokens). When a file is uploaded I simply make a POST request to a custom endpoint of the Flask webserver that allows inserting text directly in that context window. See the /inject-context Flask endpoint in the code for details.
I insert a natural language sentence describing the event “File somefilename.csv was uploaded successfully.”. When I then later ask the model something like “now print the size of the file in bytes” it knows which file I’m referring to. Presumably you can also do stuff like “the first file” and “the second file” because it has a sense of ordering in the context that’s passed along. Whether this works or not is left as an exercise for the reader ;-).
setup.py dependencies
One of the things you have to take care of as a Python package author is to specify dependencies as loosely as possible. This means you don’t pin down dependencies exactly but usually you maintain a range of major versions or a single major version depending on the versioning dynamics of the particular dependency.
That means when during development you ascertain that it “works on my machine” you can’t simply run pip freeze > requirements.txt and read requirements.txt in your setup.py and call it a day.
However, the simplicity of that process appealed to me so I figured I might be able to use a similar flow that leverages GPT-4 for the loosening of version requirements.
What I did was pipe pip list into a prompt and ask it to generate a setup.py for me that specifies the correct version ranges.
pip list:
Package Version
----------------------------- --------------
alabaster 0.7.12
alembic 1.8.1
aniso8601 9.0.1
...
xdg 5
zeroconf 0.60.0
zipp 3.8.0
requirements.txt:
ipykernel
snakemq
requests
Flask
flask-cors
python-dotenv
Write a setup.py that specifies the correct range
Generated:
setup(
...
install_requires=[
'ipykernel>=6,<7',
'snakemq>=1,<2',
'requests>=2,<3',
'Flask>=2,<3',
'flask-cors>=3,<4',
'python-dotenv>=1,<2'
],
)
On inspection it looks like it used the major version information from the pip list output to decide which major version it would pin to. I could have probably looked this up myself but this was definitely quicker and I didn’t remember the exact syntax for version ranges in setup.py so that saved me one more documentation search.
File download
I’m using a prompt that wraps the user input in order for the model to generate the correct code without any additional surrounding outputs. For example, I explain the model it should write code in Python and I inform the model the code will be executed in a Jupyter kernel context (meaning it knows it can also run bash commands like !tar -xvf archive.tgz). Because it sometimes ignores my request to not prepend/append commentary I regex out the code snippet by searching for ` or ``` markers.
Through the prompt I wanted to teach the model how to allow users to download their files. It turns out you can just teach the model with a few shot approach. The full prompt then becomes (which can likely be optimized a lot):
First, here is a history of what I asked you to do earlier. The actual prompt follows after ENDOFHISTORY. History:
<messages buffer>
ENDOFHISTORY.
Write Python code that does the following:
<user prompt>
Note, the code is going to be executed in a Jupyter Python kernel.
Last instruction, and this is the most important, just return code. No other outputs, as your full response will directly be executed in the kernel.
Teacher mode: if you want to give a download link, just print it as <a href='/download?file=INSERT_FILENAME_HERE'>Download file</a>. Replace INSERT_FILENAME_HERE with the actual filename. So just print that HTML to stdout. No actual downloading of files!
Anecdotally it looks like these instructions are picked up much more consistently by GPT-4 compared to GPT-3.5 (which makes sense).
Downloading of files is particularly useful when you ask the model to do something with your file. E.g. resizing an image.
Open Source
I have no plans to make any money from this project whatsoever. In fact, I just wanted to build this thing because I wanted to have a sandbox to tinker with code prompting & direct code execution myself. I think the most powerful thing to do is to release this as an open source project such that the broader community can extend it and keep up with the pace of innovation in LLMs.
For example, I want to support hooking this into various open source models. Like StarCoder that’s available through Hugging Face.
Ideally we’d get closer to parity to ChatGPT Code Interpreter with support for rich media outputs (which is almost in there already, probably just requires some clever parsing of the rich media output messages generated by the Jupyter kernel - maybe your first PR?).
So if you feel like contributing please go to https://github.com/ricklamers/gpt-code-ui and pick up something you like. If you think it’s cool but can’t contribute, please just give it a ⭐️ and tell your friends.
Open for work
Also, I’ve recently folded my startup Orchest and am looking to work on interesting machine learning engineering projects starting next month. If you’re interested in hiring me as a contractor please reach out, I’d love to hear what you’re building. My email is ricklamers at gmail dot com.